[1.4] XL Language Syntax Digest
This section explains the minimum syntax of the XL language in order to describe the protocols implemented in the layers above the XL layer. Firstly, the basic types of the XL language are as follows.
i) symbol (tag)
SYMBOL ::= . (escape characters <>()'",/ )
ii) string
STRING ::= .*
iii) signed integer
INTEGER_DEC ::= [1-9][0-9]*
INTEGER_OCT ::= 0[0-7]*
INTEGER_HEX ::= 0x([0-9]|[a-f]|[A-F])*
INTEGER_1 ::= INTEGER_DEC|INTEGER_OCT|INTEGER_HEX
INTEGER ::= (+|-)INTEGER_1 | INTEGER_1
iv) floating point number
MANTISSA_1 ::= [0-9]*\.[0-9]*
MANTISSA_2 ::= [0-9]*
EXPONENTIAL ::= (+|-)[0-9]*
FLOATING ::= (MANTISSA_1 | MANTISSA_2) (E|G|e|g) EXPONENTIAL
v) raw data
RAW ::= #BYTE]....
This is the escape sequence for the raw binary data transimssion
embedded in the string of the stream.
A decimal number is embedded in BYTE and as many bytes of raw data as specified by this number is placed instead of "...." Other than the basic types, there are two compound types, LIST and NULL, which combine the basic types above. These types are defined by the following syntax. In particular, the LIST type that starts with a SYMBOL is called the ELEMENT format.
Next, the syntax structure is as follows.
( sp1 is regarded as a number of contiguous white-space, line feed and tab characters. sp is regarded as sp1 or a 0length character string.)
/* XML syntax */
xml-elements ::= xml-element
| xml-element sp xml-elements
;
xml-element ::= start-tag sp1 xml-data sp1 end-tag
| empty-tag
;
xml-data-list ::= sp
| xml-data-list sp1 xml-data
;
xml-data ::= xml-element
| list-type
| '^' lisp-element
| xml-string
;
xml-string ::= STRING
start-tag ::= '<' SYMBOL sp attributes '>'
| '<' SYMBOL '>'
empty-tag ::= '<' SYMBOL '/' '>';
end-tag ::= '<' '/' SYMBOL '>';
/* LISP syntax */
lists ::= sp
| list-type sp lists
;
lisp-elements ::= sp
| lisp-elements sp1 lisp-element
;
lisp-element ::= lisp-terminal-list
| '(' sp ')' sp /* NULL type */
| list-type sp /* LIST type */
| '\'' lisp-element /* = (quote lisp-element) */
;
list-type ::= '(' sp lisp-elements sp ')'
;
lisp-terminal-list ::= sp
| lisp-terminal
| lisp-terminal sp1 lisp-terminal-list
;
lisp-terminal ::= '"' STRING '"'
| SYMBOL
| '[' sp SYMBOL attributes sp ']'
| INTEGER
| FLOATING
| RAW
;
/* shared syntax */
attributes ::= attribute
| attribute sp1 attributes
;
attribute ::= SYMBOL sp '=' sp '"' STRING '"'
;
The NULL and LIST types are defined as compound types based on lisp-elements using the syntax above. If lisp-terminal, the first element of the LIST type, is a symbol, that lisp-element is regarded as the same as an xml-element with the same symbol name. Thus the XL language as a whole is structured as follows.
/* start terminator */
XL-language ::= lists | xml-elements;
Finally, the character codes received from the streams are discussed. Basically, the character codes that can be transmitted via the streams must conform to open standards. The XL language not only functions as a description language for a package of complete programs of finite lengths, but can also be used directly as a communication protocol where it waits in an infinite loop for lines of various unrelated expressions to be processed. Thus, it must tolerate various changes in transmission status. For example, it must be possible to change encoding or insert binary data in the middle of a character string.
For this reason, the following escape codes are introduced.
-
It is possible to change character encoding if lt;code representing a character>;" is received while in the XML mode.
-
If "#<number of bytes>]" is received while in the LISP mode, the subsequent number of bytes indicated by the argument "<number of bytes>" is interpreted as binary data.
Flexible communication can be achieved by introducing the escape codes above.
The source code for the XL language lexical analyzer is found in src/xl/lib/lisp/xllisp_lex.c and the source code for the parser is found in src/xl/lib/lisp/xllisp_parser.c.
[UP]
[1.7] Remote Evaluation Procedure (Reference Model (2))
This procedure opens a stream in a layer below the XL layer. There are basically two ways of opening a stream, active open and passive open. A data communication function and a function that closes a stream and interpreter are also provided in this procedure.
First of all, a procedure for opening the XL layer, open, is provided. A parameter indicating whether to open the stream in either passive or active mode can be specified for the open procedure. Upon receiving an active open request, the XL layer sends a request to open a stream in the active mode to the specified address and port. When the stream is opened, an interpreter is assigned to the stream. This completes the active open processing of the XL layer. The following parameters are required for active open.
open active
Agent: all
Arguments:
1. Address of the target host
2. Port number of the target host
3. Environment used by the interpreter on the local
host for evaluation
Return value:
Interpreter ID
Conversely, upon receiving a passive open request, the XL layer sends a request to open a stream in the passive mode to a certain port. After that, the XL layer waits to receive a request to open a stream from another host. If it receives a stream open request, it checks the permissions related to the connection. If it is judged that the connection is possible, it opens the stream and assigns an interpreter to it. This completes the passive open processing of the XL layer. At least the following parameters are required for passive open.
open passive
Agent: all
Arguments:
1. Port number for awaiting connection
2. Information required for checking permissions of
the target host
3. Environment used by the interpreter on the local
host for evaluation
Return value:
None
Once a stream is opened, the XL layer returns an ID that identifies the stream and interpreter to an upper layer. The upper layer then sends an expression to the target host and obtains the evaluation result using this ID, by means of a function provided by the XL layer that allows this operation. On the passively opened side, the passive open function does not return an ID directly. It is thus all right to implement some functionality that generates an event in an upper layer when the opening actually succeeds. Information can be transferred from the XL layer to an upper layer via a return value of a function, evaluation result and various other ways. The currently available methods are explained in section 3.2.8.
The function that sends an expression from an upper layer to the stream in question has the following parameters.
remote
Agent: all
Arguments:
1. Interpreter/stream ID
2. Expression
Return value:
Evaluation result
The function that closes a stream and terminates all the related processing has the following parameters.
close
Agent: all
Arguments:
1. Interpreter/stream ID
Return value:
None
This function closes the stream specified by the stream/interpreter ID, discards the interpreter and releases/invalidates the resources reserved by the stream/interpreter. If a stream is closed on one host, the peer host can no longer send or receive an evaluation expression; the stream is closed and the interpreter discarded.
It may be a good idea to implement an appropriate action to be taken when a stream is closed only on one host, such as the XL layer generating an event to an upper layer. It is also necessary to take measures to prevent IDs from being used easily once invalidated, because if an interpreter ID is invalidated and immediately used for another interpreter, an upper layer may refer to this ID by mistake.
[UP]
[1.8] Remote Agent Call Procedure (Reference Model (3))
In this procedure, the concept of agent is introduced. An agent is defined as a process that provides various services based on the set of XL primitive functions. For example, in case of GLOBALBASE, it is possible to define an agent equipped with GLOBALBASE functions. This allows implementing various functions on one server and building a system where such functions can coexist.
Another important role of this layer is to manage timeout for recovery from failures. In case of reliable communication, there is no way of knowing in the stream layer if a remote host goes down. Basically, there is no means to distinguish whether the host went down or the network is slow. If it is carelessly judged that the host is down when it is not actually down, there is a risk that processing on the remote host side fails. The fact that the host went down is only known when the host recovers and it is realized that the state is different from the state in the previous communication. If a remote host never responds, it is not possible to judge whether or not the remote host is down forever.
One of the means to solve this problem is to set appropriate timeouts judging from the function of an application. If a remote host does not respond for more than a specified time, the stream to the host and associated processing are paused by the timeout. This timeout setting depends on the application, however. This means that it cannot be implemented in the stream layer. Thus it is appropriate to implement it as a function of this agent.
This section describes how to call an agent first and then explains how an agent handles timeout processing.
A client can call various agents on the server. An agent called by a client sends various expressions from the client and the state of the agent's environment changes depending on the order.
There are two problems involved in performing various types of processing by connecting to an agent on a remote host. One is whether or not it is possible to select an agent suited for the purpose. Another problem is that part of the agent's state data must be shared between the host and client. The consistency of this data may not be maintained between the agent and the client, which is situated at a remote location, if the line is disconnected. These problems can be solved by the remote agent call procedure.
Firstly, a function for activating an agent with the remote call procedure is defined. This expression is the one defined for an agent called xlsv ( xl server). At least one xlsv agent is activated for a server supporting the XL protocol and this xlsv agent opens an XL port. If a client connects to this open port, it is also connected to the xlsv agent at the same time. The following function must have been defined for this xlsv agent.
(SetAgent agent-name mode)
Agent: xlsv
Arguments:
STRING agent-name
STRING mode
Attributes:
version (client version)
Return value:
NULL
ERROR
invalid agent
permission denied
"SetAgent" activates an agent specified by "agent-name" in the mode specified by "mode." An agent is activated if permitted by a table of correspondences between the agent-name read by xlsv at the activation and the actually activated process name and argument. Agents that are not registered in this table cannot be activated ( permission denied/undefined agent).
The mode can be user, server, root etc., and is passed as part of the arguments to the agent invocation.
The activated agent inherits the stream that was opened between the client and xlsv as is. The expression sent after the SetAgent instruction is sent to this agent.
In many cases, an agent performs processing on some resources identified by URLs. An agent that is suited to the individual type of file should be used; for this reason, xlsv has a table of correspondences between filename prefixes and agents. The following function is used to refer to this correspondence table.
(GetPrefix method prefix)
Arguments:
STRING method (Get/Set method)
STRING prefix (URL prefix)
Attributes:
Return value:
ELEMENT list of the agent
The client can know the required agent with this function.
By using the remote call procedure and SetAgent function outlined above, it is possible to activate as many agents as one wants on one server.
By taking advantage of the aforementioned remote call procedure, it is basically possible to generate an agent on a remote host and perform communication. However, as mentioned earlier, it is necessary to implement timeout management for recovery from failure in a reliable communication system here. Basically, the following two types of timeout must be implemented.
-
Timeout when there is no communication from a remote host for a fixed period of time
-
Maximum operation time of an agent
For 1,several timeouts must be implemented for individual phases. First of all, the following timeouts should be implemented for a client.
-
Timeout of response to active open ( including permission processing etc.)
-
Timeout of response to SetAgent
is implemented at the opening of a stream as well, but must be set taking permission processing specific to the XL layer into account as well.
Next, the following timeout should be set for the server.
-
Timeout when there is no request from a client
Moreover, the following timeout should be implemented for both the client and server.
-
Timeout of response to transmission of an evaluation expression
The timeouts above have been given default values, but it may be a good idea to implement a protocol that measures each response time and dynamically changes the default value to the optimal value corresponding to a specific network.
Note that it may happen that a stream may be disconnected due to one of the timeouts above, even though there is no problem in the system. In such cases, it may be possible to perform fault recovery processing, but the problem can usually be solved more simply by setting the necessary conditions and sending the same evaluation expression again. When directly accessing the remote call procedure, it is necessary to implement unique fault recovery processing, however. The remote agent call procedure has a function to perform fault recovery processing as well.
In the remote agent call procedure, the client side assigns a session for each state of an agent in a remote host. It connects to the same agent if the session ID, connection destination server and activated agent are the same. It then generates an environment for this session to this agent and sets the necessary state. With this procedure, the same environment is never used for different sessions even if the agent is the same.
If a remote agent times out or goes down due to failure, the client tries to activate the agent again. If it is activated, the state before the failure is set up for the environment. If it turned out to be impossible to recover from failure after three attempts, it is necessary to generate an error.
One session is opened by invoking open_session, its environment is set by invoking remote_env, and the expression is sent by invoking remote_session. The session is closed by invoking close_session. How these functions are invoked is summarized below.
open_session
Agent: all
Arguments:
none
Return value:
session ID
This function opens a remote agent session and assigns a session ID to it.
remote_session
Agent: all
Arguments:
1. session ID
2. Activated agent (can be omitted)
3. Destination URL
4. Get/set operation (can be omitted)
5. user
6. mode
7. Expression
Return value:
Evaluation result of the expression returned by the
remote agent
If the activated agent is omitted, the client makes an inquiry to the remote server for a list of agents that can be activated. It selects the operation specified by the "operation" argument and an agent corresponding to the extension of the resource at the URL. If an agent is explicitly specified, it connects to that agent. "user" and "mode" are used as arguments of SetAgent. When the agent is successfully activated, the expression is sent and the evaluation result is returned as the return value of remote_session.
close_session
Agent: all
Arguments:
1. session ID
Return value:
None
This function closes the session indicated by the session ID.
[UP]
[2.1.6] Coordinate System Resource
<?xml version="1.0" encoding="EUC-JP"?>
<coordinate>
<meta>
<bib xmlns:gb="xlp://isjhp1.nichibun.ac.jp:8080/gb_metadata">
<gb:title type="text" data="Toyo University, Itakura Campus"/>
<gb:creator type="text"
data="Toyo University, Itakura Campus, Fujita Laboratory"/>
<gb:content.period type="W3C-DTF" data="1990-01-01 /"/>
<gb:issue.period type="W3C-DTF" data="2003-08-25"/>
<gb:property type="gb-prop" data="base"/>
</bib>
<file type="e2d"/>
<mr>
((0km 0km )
(1.3km 0.62km ))
</mr>
<v>
<resolution>
2dot/km
</resolution>
</v>
</meta>
</coordinate>
The special elements unique to coordinate system resources are mr ( minimum rectangle) and v ( visible). "mr" is the effective range of the coordinate system. The rectangular range is given by the pair of points for which the coordinate values along each dimension are minimum and maximum, respectively.
The "v" element specifies the condition where the coordinate is visible on the browser display. Currently, only one format is supported for this condition, providing the resolution of the display using the following format.
<v><resolution> minimum-resolution maximum-resolution </resolution></v>
or
<v><resolution> minimum-resolution </resolution></v>
When the coordinate is within the browser's display range, it will be visible if the current resolution of the browser is between these parameters. If maximum-resolution is omitted, maximum-resolution is set to 2000times larger than the value of minimum-resolution.
Another method of indicating whether to display a coordinate is by judging the distance between the coordinate and the view-point of the browser. This method will be considered when 3DGLOBALBASE is developed.
The "file" element in the coordinate system resource gives many types of coordinate systems. We assume that the characteristics of the coordinate system is given by the topological and geometric structure. Currently, the topologies of Euclidean space topology ( euclides) and globe surface topology ( globe-sur) are supported. Geometric structure is then induced by introducing a distance measure into the topology space. The Pythagorean distance is supported for the Euclidean and, globe topologies and ellipsoid distance is supported for the globe surface topology. The globe and ellipsoid distance measures require radius and long and short radius values, respectively.
According to mathematical theory ( Manifold theory), it is enough to support Euclidean topology. For the sake of user convenience, however, we implemented support for the globe surface topology as well, as it provides an easy framework for describing the surface of the Earth.
In the future, it will be possible to define many non-Euclidean geometric structures, for instance Minkovskian geometry, embedded in euclides, and we will eventually be able to describe the whole universe within the GLOBALBASE framework.
The format of the "file" element is
<file="[topology];[geometry];[parameters];[axis]"/>
and we provide certain macro descriptions, such as "e2d" for often-used parameter values. "e2d" stands for Euclidean 2Dspace, and specifying this macro is equivalent to specifying the following parameter values.
euclides;pythagoras;comp
The "axis" argument gives the direction of the coordinate axis, “math” specifies the mathematical coordinate system and “comp” indicates that the computer coordinate system is used.
[UP]
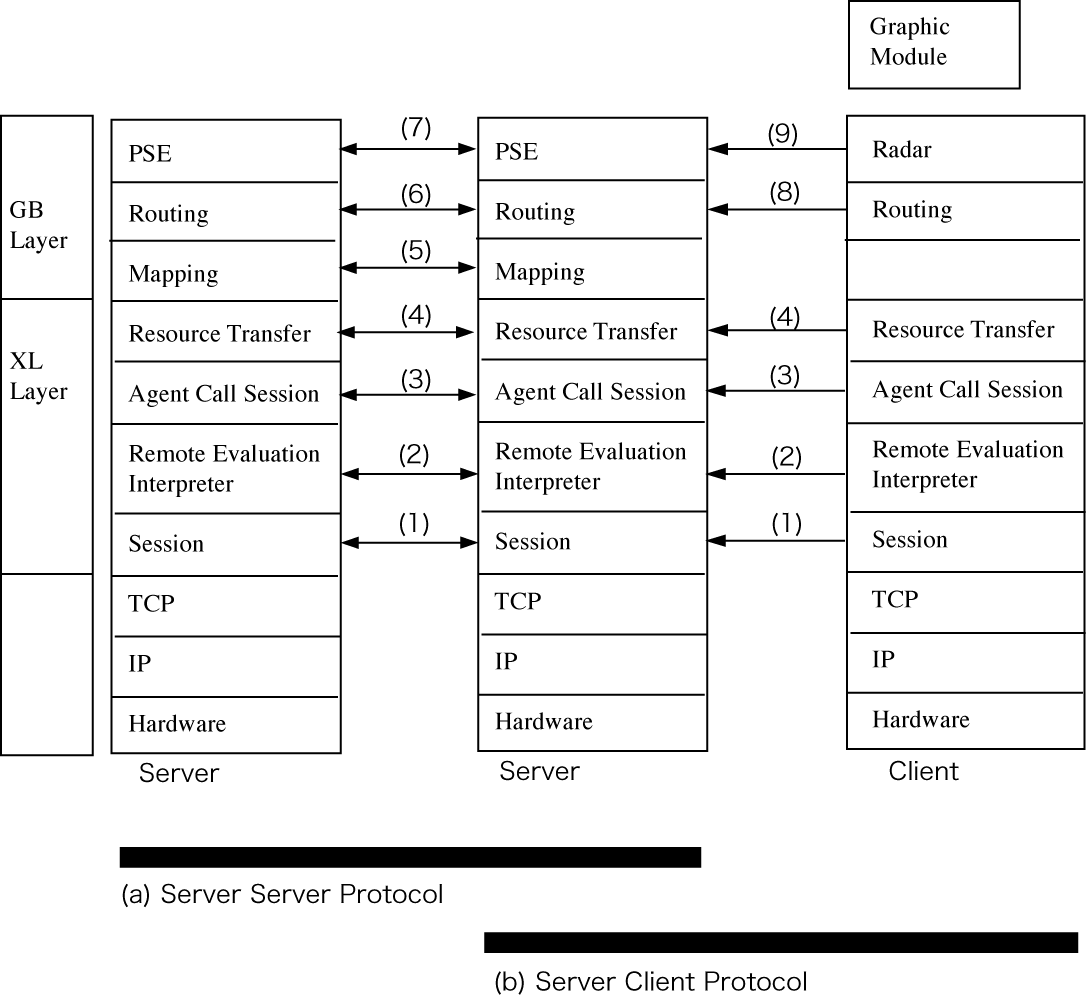
[2.5] Routing Layer (Reference Models (6) and (8))
The role of the routing layer is to provide a service that returns a list of mappings ( called mapping path) that traces a path between two given arbitrary coordinate systems ( coordinate system resources).
GLOBALBASE can be regarded as a collection of overlay networks superimposed on the Internet, where mappings and relationships between resources can be seen as vertices and other resources can be seen as nodes. On a slightly higher level of abstraction, since object resources are always connected to coordinate systems, which are in turn connected by mappings, GLOBALBASE can, in fact, be considered a set of overlay networks consisting of only coordinate system resources and mappings.
In this way, an algorithm that searches for a mapping path between two arbitrary coordinate systems is equivalent to an algorithm that assigns route selectable addresses to all coordinate systems and performs routing among these addresses.
In GLOBALBASE, ACRP ( Auto-Configurated Routing Protocol) is employed for this algorithm. ACRP is an algorithm that extends RIP ( Routing Information Protocol) to automatically deliver path selectable information and assign a path selectable address to each node ( coordinate system resource), which eliminates the trouble of having to manually assign route selectable addresses from information providers of GLOBALBASE. The basic algorithm of ACRP has been published in a paper [2], and the detailed algorithm used for GLOBALBASE will be introduced as a separate RFC. This RFC only describes how to determine the basic information and the protocol for exchanging information between servers as well as between server and client.
A route selectable address assigned to an individual coordinate resource is called a coordinate system ID. This ID is an address of a variable length with a subnet address value from 0to It can for example be expressed as ( cid 3345This address is the same as ( cid 03345or ( cid 003345which have additional leading zeros. When the number of coordinate systems increase and the range of assigned addresses is extended, the old addresses are interpreted as being equivalent to the new addresses with additional zeros.
One of the major features of ACRP is that a unique priority must be specified for each coordinate system resource. Fortunately, in GLOBALBASE, a URL unique to each resource has already been assigned; this character string can be specified as a priority. Moreover, it is desirable to assign higher order to older priorities, so that the older information has higher stability. Hence, the following character string is defined as the priority, so that the smaller the character string when compared alphabetically, the higher the priority.
time, octal 11-digitformat]:[domain name of url]:[port-no of url]:[path name of url]
The XL time above is the number of seconds elapsed since 0o'clock midnight on January 1,If it should happen that the XL time cannot be expressed in octal 11-digitformat, the first character can be set to 1and the number of digits increased.
The route selection table of ACRP is stored in the management information of each coordinate system resource. This table is called a mapping path table in GLOBALBASE, and has the following entries.
<?xl encoding=".." version="1.0"?>
<mpt>
<cid pri="...."> id0 id1 </cid>
<regulation> interval </regulation>
<level> 1
<entry> id0-entry "priority" sum
<dir> hops "map" "crd" </dir>
.....
</entry>
....
</level>
<level> 0
....
</level>
</mpt>
The cid element above indicates an ID assigned to a coordinate system. The pair of integers, i.e., id0 and id1, which can take values from 0to 127,are concatenated to form the coordinate system ID. As the number of coordinate systems increase, this list of integers may become longer, i.e., 3integers, 4integers and so on. The pri attribute of the cid tag indicates the priority of the coordinate system in this overlay network that has the highest priority. This value must be consistent in all coordinate systems existing in a connected network. Thus, it is possible to check whether or not routing is possible in advance by looking at this value.
"regulation" indicates the regulation interval based on the ID assignment algorithm ACRP. The unit is seconds and "interval=0" signifies that the address and table are determined.
The level element is a routing table at the level corresponding to id0 and id1. The number of levels naturally increases as the number of concatenated IDs increases. An entry element corresponding to the ID is prepared for each level. "id0-entry" indicates the ID and "priority" indicates the priority of this entry ( see ACRP [2]). "sum" is the number of coordinate systems belonging to the address indicated by this entry and "dir" indicates the routing destination for reaching the address of this entry. If there are two or more systems, the two routing destinations with the least number of hops are stored. From this coordinate system, it is possible to route to "crd" via "map."
If the "id0-entry" data of the "entry" element is equal to id0, it means the resource itself; thus hops=0, "map" = "" and "crd" = "".
An example of a routing table of a coordinate system is shown below.
([?xl eoncoding="EUC-JP" version="1.0"])
(mpt
([cid
pri="000334750032:tois1.nichibun.ac.jp:8080:/tois/gyouji/gyouji11.crd"]
31 56)
(regulation 0)
(level 1
(entry 127
"000334750573:isjhp1.nichibun.ac.jp:8080:/nichibunken/uno/thysen/4new-kuro.crd"
1
(dir 2
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/uno/uno1/uno1.no6.map"
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/uno/uno1/uno1.crd"))
(entry 126
"000334750537:isjhp1.nichibun.ac.jp:8080:/nichibunken/uno/thysen/1old-kuro.crd"
1
(dir 2
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/uno/uno1/uno1.no6.map"
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/uno/uno1/uno1.crd"))
(entry 125
"000334750512:isjhp1.nichibun.ac.jp:8080:/nichibunken/isjhp/Heian/6/base.crd"
1
(dir 1
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/isjhp/Heian/6/base.map"
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/isjhp/Heian/6/base.crd"))
(entry 124
"000345677213:isjhp1.nichibun.ac.jp:8080:/lib/maizo/iseki/h2_107_fig15-1.crd"
1
(dir 2 "xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.map"
"xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.crd"))
(entry 123
"000334750674:isjhp1.nichibun.ac.jp:8080:/lib/ku/1637/road.x.crd" 1
(dir 1 "xlp://isjhp1.nichibun.ac.jp:8080/lib/ku/1637/road.x.no6.map"
"xlp://isjhp1.nichibun.ac.jp:8080/lib/ku/1637/road.x.crd"))
......
(entry 56 "000345676725:isjhp1.nichibun.ac.jp:8080:/kokudo/coord/no6.crd" 1
(dir 0 "" ""))
......
(entry 5
"000334750635:isjhp1.nichibun.ac.jp:8080:/nichibunken/uno/thysen/furuold-all.crd"
1
(dir 2
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/uno/uno1/uno1.no6.map"
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/uno/uno1/uno1.crd"))
(entry 4
"000512015314:tois1.nichibun.ac.jp:8080:/tois2/gyouji/gyouji3.crd" 1
(dir 2 "xlp://tois1.nichibun.ac.jp:8080/kokudo/coord/no6.map"
"xlp://tois1.nichibun.ac.jp:8080/kokudo/coord/no6.crd"))
(entry 3
"000334750555:isjhp1.nichibun.ac.jp:8080:/nichibunken/uno/thysen/3new-all.crd"
1
(dir 2
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/uno/uno1/uno1.no6.map"
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/uno/uno1/uno1.crd"))
(entry 2
"000334750521:isjhp1.nichibun.ac.jp:8080:/nichibunken/isjhp/Heian/9/base.crd"
1
(dir 1
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/isjhp/Heian/9/base.map"
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/isjhp/Heian/9/base.crd"))
(entry 1
"000345677377:isjhp1.nichibun.ac.jp:8080:/lib/maizo/iseki/h2_203_fig96-3.crd"
1
(dir 2 "xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.map"
"xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.crd"))
(entry 0
"000412325271:tois1.nichibun.ac.jp:8080:/tois2/gyouji/gyouji6.crd" 1
(dir 2 "xlp://tois1.nichibun.ac.jp:8080/kokudo/coord/no6.map"
"xlp://tois1.nichibun.ac.jp:8080/kokudo/coord/no6.crd")))
(level 0
(entry 125
"000346676734:isjhp2.nichibun.ac.jp:8080:/kokudo/coord/06.crd" 10
(dir 1 "xlp://isjhp1.nichibun.ac.jp:8080/kokudo/coord/no6.map"
"xlp://isjhp2.nichibun.ac.jp:8080/kokudo/coord/06.crd"))
(entry 124
"000346676726:isjhp2.nichibun.ac.jp:8080:/kokudo/coord/08.crd" 11
(dir 3 "xlp://isjhp1.nichibun.ac.jp:8080/kokudo/coord/no6.map"
"xlp://isjhp2.nichibun.ac.jp:8080/kokudo/coord/06.crd"))
(entry 122
"000345677331:isjhp1.nichibun.ac.jp:8080:/lib/maizo/iseki/h2_203_fig96-1.crd"
1
(dir 2 "xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.map"
"xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.crd"))
.......
(entry 39 "000346676705:isjhp2.nichibun.ac.jp:8080:/kokudo/coord/15.crd" 4
(dir 3 "xlp://isjhp1.nichibun.ac.jp:8080/kokudo/coord/no6.map"
"xlp://isjhp2.nichibun.ac.jp:8080/kokudo/coord/06.crd"))
(entry 33
"000421014012:isjhp1.nichibun.ac.jp:8080:/lib/maizo/iseki/h2_203_fig96-4.crd"
1
(dir 2 "xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.map"
"xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.crd"))
(entry 31
"000334750035:tois1.nichibun.ac.jp:8080:/tois/gyouji/gyouji9.crd" 128
(dir 0 "" ""))
(entry 30
"000345677206:isjhp1.nichibun.ac.jp:8080:/lib/maizo/iseki/h2_108_fig18-1.crd"
1
(dir 2 "xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.map"
"xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.crd"))
(entry 27 "000346676713:isjhp2.nichibun.ac.jp:8080:/kokudo/coord/13.crd" 2
(dir 3 "xlp://isjhp1.nichibun.ac.jp:8080/kokudo/coord/no6.map"
"xlp://isjhp2.nichibun.ac.jp:8080/kokudo/coord/06.crd"))
(entry 25
"000345677314:isjhp1.nichibun.ac.jp:8080:/lib/maizo/iseki/h2_106_fig09-2.crd"
1
(dir 2 "xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.map"
"xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.crd"))
.......
(entry 3
"000345677214:isjhp1.nichibun.ac.jp:8080:/lib/maizo/iseki/h2_130_fig75-2.crd"
1
(dir 2 "xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.map"
"xlp://isjhp1.nichibun.ac.jp:8080/lib/maizo/iseki/no6.crd"))
(entry 0
"000334750032:tois1.nichibun.ac.jp:8080:/tois/gyouji/gyouji11.crd" 1
(dir 2 "xlp://tois1.nichibun.ac.jp:8080/kokudo/coord/no6.map"
"xlp://tois1.nichibun.ac.jp:8080/kokudo/coord/no6.crd"))))
This mapping table is exchanged regularly between adjacent coordinate resources. In RIP, the routing table is exchanged among nodes via broadcast, but in GLOBALBASE, this exchange is achieved by obtaining a route selection table from the adjacent coordinate resource. This approach is taken both because our protocol does not have any broadcast mechanism, as well as in order to prevent a routing table from being sent automatically from an irrelevant resource that is not in the mapping list of the management information. Moreover, in RIP, in order to know a node adjacent to a certain node, it is necessary to scan the interface for that purpose only, which is wasteful processing, whereas GLOBALBASE allows going to the surrounding coordinate system resources directly, because mapping lists are prepared for all resources by lower layers.
The mapping path table of a coordinate system resource is obtained by providing the attribute mode="mpt" ( mapping path table) to the Get expression as shown below.
([Get mode="mpt"] url)
Agent: gbstd
Arguments:
STRING url
Attributes:
STRING mode
Return value:
LIST (mapping path table)
There are cases where updates of a certain coordinate system and/or mapping should be reflected in the mapping path table as soon as possible. The following expression has been prepared for such cases.
(MPtrigger url)
Agent: gbstd
Arguments:
STRING url
Attributes:
None
Return value:
NULL
By issuing this expression to a target URL, the mapping path table is forcefully rebuilt.
Lastly, expression formats for obtaining a mapping path between two arbitrary coordinate system resources, are shown below.
(MProuting url1 url2)
Agent: gbstd
Arguments:
STRING url1
STRING url2
Attributes:
None
Return value:
LIST (mapping path)
(MProuting url1 cid)
Agent: gbstd
Arguments:
STRING url1
ELEMENT cid
Attributes:
None
Return value:
LIST (mapping path)
The first expression format takes two resources specified as URLs as input arguments, while the latter expression format obtains the mapping path between resources given by "url1" and "cid." "cid" is passed to the Get function using the following format.
(cid subaddr1 ...)
Agent: all
Arguments:
INTEGER subaddr1 ...
Attributes:
STRING body
Return value:
None
The address is indicated in place of "subaddr1." It is not necessary to specify "body," but doing so indicates the highest priority in the overlay network to which this resource belongs. If the body value is different for two resources, these two resources belong to different independent overlay networks and no mapping path exists between them.
The format of the mapping path returned by the operation above, is as follows.
(mapping coordinate mapping coordinate ....)
As can be seen, this is a list where URLs of mapping resources and URLs of coordinate system resources are repeated alternately. The mapping resource at the start of the list is adjacent to url1 and the last coordinate system resource is always the coordinate system specified by url2 or cid.
See src/gbs/lib/mp/routing.c and src/gbs/lib/mp/acrp.c for the source code implementing the routing algorithm on the server side, and src/gbs/lib/view/routing.c for the source code implementing the routing algorithm on the client side.
[UP]
[2.7.2] Lump Generation
In most cases, one lump exists on each server. However, several lumps can exist on one server or several servers can share one lump, depending on the range in which information is collected. Each lump is connected to one coordinate system resource residing on the server on which it exists. Basically, it has the same URL as the coordinate resource.
In normal search engines, resources do not register themselves in a search engine on their own. In case of PSE, however, each resource registers itself within appropriate search engines. For this reason, the PSE can be updated immediately whenever a new resource is loaded into a server or a resource is deleted from a server.
In order to implement this mechanism, each coordinate system resource traces the overlay network and stores the nearest five lumps in its management information by itself. This is called lump information. The coordinate system resource then registers its bibliographical information to these five lumps. The lump information has the following format.
<?xl .... ?>
<lump-info>
[
<option>
[ <lump> "lump-path" </lump>]
[ <destroy> time </destroy>]
[ <launch> time </laumch>]
[ <fade> time interval </fade>]
</option>
]
<entry> "lump-crd" "crd" pri hops hops-max </entry>
[ <entry> "lump-crd" "crd" pri hops hops-max </entry>
<entry> "lump-crd" "crd" pri hops hops-max </entry>
<entry> "lump-crd" "crd" pri hops hops-max </entry>
<entry> "lump-crd" "crd" pri hops hops-max </entry>
]
</lump-info>
[] can be omitted.
The entry element indicates the five lumps ( lump-crd) closest to this coordinate system and the coordinate system ( crd) adjacent to it in the direction where each of the lumps exists. "pri" is the priority of each of the lumps ( the time when the lump was generated), "hops" is the number of hops required to reach the lump, and "hops-max" is the maximum number of hops. Lumps farther than "hops-max" cannot be seen from this coordinate system.
"hops-max" is set by the lump itself and is set to a large value when the capacity of the lump is large and a large amount of information can be stored. The older the time of generation, the higher the value of "pri" becomes.
The lump element within the option tags indicates that a lump exists for the coordinate system and the contents of the element provides the path to the lump.
The destroy element is specified when it is judged that there are many lumps in the vicinity of the coordinate system that the lump is attached to and indicates the time at which this lump is destroyed. If it is judged that the density of surrounding lumps has become lower by this time, the destroy element is deleted.
The launch element, on the contrary, is specified when the density of surrounding lumps is too low in the vicinity of a coordinate system without any lump attached, and it is necessary to create new lumps. The element indicates the time at which a new lump is launched. The times specified in the "destroy" and "launch" elements are set with some margins, rather than immediately after the judgment.
The fade element indicates the time interval at which to acquire the surrounding conditions again after a lump was launched or destroyed, or the surrounding conditions have changed and the contents of the entry element have changed. The value of this time interval gradually becomes larger, and the checking caused by "fade" is ended when the value reaches a set value.
The following shows two examples of lump information. i. An example of a coordinate system without a lump
([?xl encoding="EUC-JP" version="0.1"])
(lump-info
(entry
"xlp://vkyoto.sd.docomo-kansai.co.jp:8080/v-kyoto/kyoto-map/kyoto.crd"
"xlp://isjhp2.nichibun.ac.jp:8080/kokudo/coord/06.crd" 83138304 3 9)
(entry "xlp://isjhp2.nichibun.ac.jp:8080/kokudo20000/coord/05.crd"
"xlp://isjhp2.nichibun.ac.jp:8080/kokudo/coord/06.crd" 77024699 3 9)
(entry "xlp://tois1.nichibun.ac.jp:8080/tois/gyouji/gyouji11.crd"
"xlp://tois1.nichibun.ac.jp:8080/kokudo/coord/no6.crd" 57921589 2 9)
(entry "xlp://gbs.kyoto-archives.gr.jp:8080/kyoto2500/kyoto2500.crd"
"xlp://isjhp2.nichibun.ac.jp:8080/kokudo/coord/06.crd" 87731039 2 9)
(entry
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/isjhp/Heian/4/base.crd"
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/isjhp/Heian/4/base.crd"
57921893 1 9))
ii. An example of a coordinate system with a lump
([?xl encoding="EUC-JP" version="0.1"])
(lump-info
(option
(lump "/work/lump/0/0/0/246/"))
(entry
"xlp://vkyoto.sd.docomo-kansai.co.jp:8080/v-kyoto/kyoto-map/kyoto.crd"
"xlp://isjhp1.nichibun.ac.jp:8080/kokudo/coord/no6.crd" 83138304 4 9)
(entry "xlp://isjhp2.nichibun.ac.jp:8080/kokudo20000/coord/05.crd"
"xlp://isjhp1.nichibun.ac.jp:8080/kokudo/coord/no6.crd" 77024699 4 9)
(entry "xlp://tois1.nichibun.ac.jp:8080/tois/gyouji/gyouji11.crd"
"xlp://isjhp1.nichibun.ac.jp:8080/kokudo/coord/no6.crd" 57921589 3 9)
(entry "xlp://gbs.kyoto-archives.gr.jp:8080/kyoto2500/kyoto2500.crd"
"xlp://isjhp1.nichibun.ac.jp:8080/kokudo/coord/no6.crd" 87731039 3 9)
(entry
"xlp://isjhp1.nichibun.ac.jp:8080/nichibunken/isjhp/Heian/4/base.crd" ""
57921893 0 9))
This format is the same as for some of the routing information; the only difference is the inclusion of the number of hops and the path to the lump. A coordinate system resource obtains and merges surrounding lump information regularly, placing higher priority on the direction with the minimum number of hops to reach the same lump. This algorithm is thus an implementation of the distributed Dijkstra shortest path algorithm. If the coordinate system resource finds information of more than six lumps, the information is deleted and not stored as management information.
A coordinate system resource with a lump, naturally, knows the positions of four lumps in addition to that of its own lump. If the positions of these four lumps are too close to the position of its own lump, it destroys its own lump. Conversely, if a coordinate system resource without a lump is positioned too far away from the nearest surrounding lumps, it generates a lump attached to itself. There are various algorithms for judging the limit of what should be regarded as too far or too close. In the current implementation, a lump is generated if no lump exists in the vicinity on the server on which the coordinate system resource resides. With this algorithm, however, too many lumps may be generated if there are many servers with few resources each, which can be a problem.
See src/gbs/mp/lump.c for the source code dealing with lump management.
[UP]
[2.7.4] Searching Query
The following expression is used to search for resources registered in a lump.
(PMDquery db rect reso-min reso-max filter)
Agent: gbpmd.get
Arguments:
STRING db
LIST rect
FLOATING/INTEGER reso-min
FLOATING/INTEGER reso-max
LIST filter
Attributes:
format long or short (short if omitted)
Return value:
LIST Search result list
The features of this search query is that the geographical range ( rect) and resolution ( reso-min/reso-max) of the search are specified. They correspond to the range displayed in a browser and its resolution. "rect" is a list of two points, with each point being a list of two numerical values, specifying the coordinates of the points at which the x and y coordinate values of a rectangle become the minimum and maximum, respectively. That is, a rectangle is specified using the following format.
((0.0km 1.5km) (100km 20km))
When target resources is narrowed down in this way, the bibliographical information matching the data specified by a filter is acquired. The format of the filter is described as a combination of qualifier and URL functions with AND, OR and NOT operators, for instance as follows.
(OR (AND
([qualifier cond="part"]
"xlp://isjhp1.nichibun.ac.jp:8080/gb_metadata"
0
"property"
()
"base")
([qualifier cond="boundary"]
"xlp://isjhp1.nichibun.ac.jp:8080/gb_metadata"
0
"content.period"
"W3C-DTF"
"2003-10-27 / 2003-10-27"))
(URL "xlp://isjhp2.nichibun.ac.jp:8080/world/00.crd"))))
The structure of each function is defined as follows.
(AND ...)
Agent: gbpmd.get
Arguments:
gbpmd.get Type specified within an agent
Attributes:
Return value:
gbpmd.get Specified within an agent
(OR ...)
Agent: gbpmd.get
Arguments:
gbpmd.get Type specified within an agent
Attributes:
Return value:
gbpmd.get Specified within an agent
(NOT query)
Agent: gbpmd.get
Arguments:
gbpmd.get Type specified within an agent
Attributes:
cond part,boundary, match (match if omitted)
Return value:
gbpmd.get Specified within an agent
(qualifier namespace inheritance name type data)
Agent: gbpmd.get
Arguments:
STRING namespace
INTEGER inheritance
STRING name
STRING type
STRING data
Attributes:
cond part, boundary, match (match if omitted)
Return value:
gbpmd.get Specified within an agent
(URL url)
Agent: gbpmd.get
Arguments:
STRING url
Attributes:
cond part, boundary, match (match if omitted)
Return value:
gbpmd.get Specified within an agent
There are three types of result resources lists: a list consisting only of URLs ( format="short"), a list containing ranges and flags indicating which conditions are matched ( format="middle") in addition to the above, and a list containing all data including biographical information ( format="long").
[UP]